计算机视觉及智能影像行业深度研究报告
1. 计算机视觉领跑 AI 产业,应用场景广阔
1.1 什么是计算机视觉?让机器“看懂”影像的 AI技术
计算机视觉是 AI 核心研究领域,目的在于让机器具备人类的“眼力”。计算机视觉是人工智能的 分支之一,目的在于通过电子化的方式来感知和理解影像,让计算机具备和人一样的"眼力",能够 识别、理解周围的世界。人脑接受的 80%的信息来自眼睛(视觉),50%的大脑活动都与处理视觉 信息有关,可见视觉在信息传递中的重要性和复杂性。
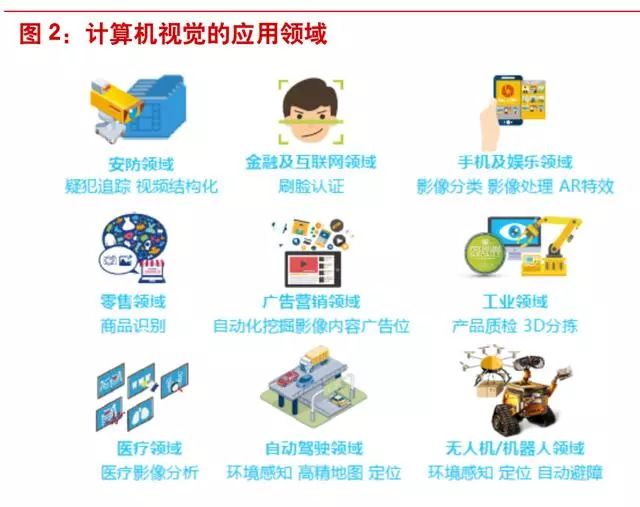
应用场景广阔,技术价值巨大。计算机视觉应用领域广阔,包括安防中的智能监控、人脸识别,金 融中的身份验证,零售中的商品识别,自动驾驶,文娱领域智能营销、AR 特效等,技术价值巨大。
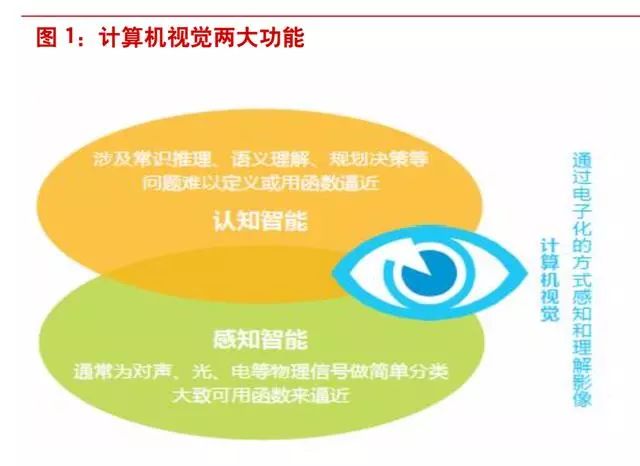
为了“看懂”世界,计算机必须具备两大能力——感知智能和认知智能,通过两大能力,计算机将 感知到图像中包括哪些物体、人、物,并识别表达。
能力 1 ——感知智能:图像中有什么
感知能力既通过方法,机器可知道影像中有什么,主要是局部像素分类及识别,如物体和人的识别、 分类、定位等。以下图为例,计算机视觉的感知智能即为识别出图像中包括了狗、猫、花朵、篮子、 绿叶这些物体。

从具体技术来看,视觉感知智能有 5 大核心技术,分别为图像分类、物体定位、物体识别、语义分 割、三维重建。
图像分类:根据图像主要内容进行分类。此为最基本视觉任务,它将一副图像分类到一个属 于已知的类别集合中的类别,比如将带有猫的图片归属到猫类。流行的基本方法就是用深度 卷积网络(CNN)提取特征并分类,将图片输入网络直接得到物体的类别。
物体定位:定位包含主要物体的图像区域,以便识别区域中的物体。当一副图像内的不同位置 存在不同物体时那就不能简单地将图片分为某一类了。这时需要找出图像中有几类物体,准确 地标注出它们所在位置,并把物体在图像中框出来。
语义分割:把图像中每一个像素分到其所属物体类别。用目标检测方法把物体在图像中框出来, 框一般是用矩形框,但物体一般是流线形的,为了进一步标注出物体,需要指出图像中哪些像 素是对应哪一类的物体——既图像语义分割,效果如下图所示(图 3)。语义分割可看做分类 问题,可以借鉴分类算法把每一个像素划分到某一类物体。
物体识别:定位并分类图像中出现的所有物体。这一过程通常包括:划出区域然后对其中的 物体进行分类。此为图像分类、物体定位和语义分割的结合。
三维重建:由二维图像升级到立体视觉。三维重建一般是指基于二维图像通过图像预处理、 点云配准与融合、生成表面等过程把真实的三维场景从二维图像中恢复出来。
能力二——认知智能:图像表达了什么
在图像识别基础上,机器还需知道各个局部之间关系、整体关系,即理解和推断物体之间关联,推 测人的情绪和意图,对整体场景判断等,甚至进行决策。具体如下图:
1)图像识别:男士、女士、餐桌、酒杯、食物、鲜花、灯光
2)人物的动作、表情以及情绪:吃东西、微笑、快乐
3)图像各部分的关联:男女注视对方、男女是情侣关系、男女在餐桌上吃饭
4)整体场景的含义:一对情侣在餐厅约会,彼此很开心

具备了感知智能和认知智能,计算机就可以像人脑一样处理视觉信息,甚至在识别人脸、物体和场 景的准确率上超过人类,并且在此基础上进行推理、决策。而这种能力洽洽是安防、自动驾驶、金 融、医疗等领域存在强烈需求,计算机视觉技术随着不断成熟将广泛应用于各个行业。
1.2 计算机视觉领跑 AI 产业,安防领域应用最深
计算机视觉是中国 AI 行业的最大组成部分,市场规模飞速增长。根据中国信通院报告数据,2017 年中国人工智能市场中计算机视觉占比 37%,据艾瑞咨询预测 2018 年计算机视觉市场规模达 120 亿元。从全球来看,MarketsandMarkets报告显示,2017 年基于人工智能的计算机视觉全球市场规 模为 23.7 亿美元,预计 2023 年会达到 253.2 亿美元,预测期内复合年增长率 47.5%。
